

By Wenzhe Yang, Shloak Gupta, Ania Korsunska, Jennifer Stromer-Galley
Political messaging covers a broad range of issues that can be clustered into groups, such as foreign policy, immigration, and economic issues. Identifying topics in candidates’ social media messages allows us to better understand which issues they emphasize in their campaigning, and it allows us to compare the frequency with which different candidates discuss a given topic. In other words, by analyzing the distribution of topics in campaign messages, we gain more comprehensive insight into the candidates’ campaign strategies.
1. Introduction
We developed a set of 12 political topics that presidential campaigns emphasize in their political platforms. These topics were developed inductively over several election cycles. We initially developed a list of over 25 topics and through a variety of approaches, we narrowed down the list to 11 topics plus the COVID-19 topic, for which we adapted the lexicon from this keyword list.
We used a lexicon-based method to identify topics in social media messages. This method combines the pre-trained English language model Spacy English with a feature-word lexicon. The core of our “topic detector“ is a political topic lexicon, which contains lists of n-grams that serve as language cues for each of our topics. The n-gram is a contiguous sequence of n items from a given sample of text or speech. These items can be a combination of phrases and/or words. The lexicon’s seed words originally come from primary debate transcripts and convention speeches, though we have further developed our lexicon with the help of Illuminating’s annotation team and machine learning algorithm. Figure 1, below, shows the workflow for our message topic classification:
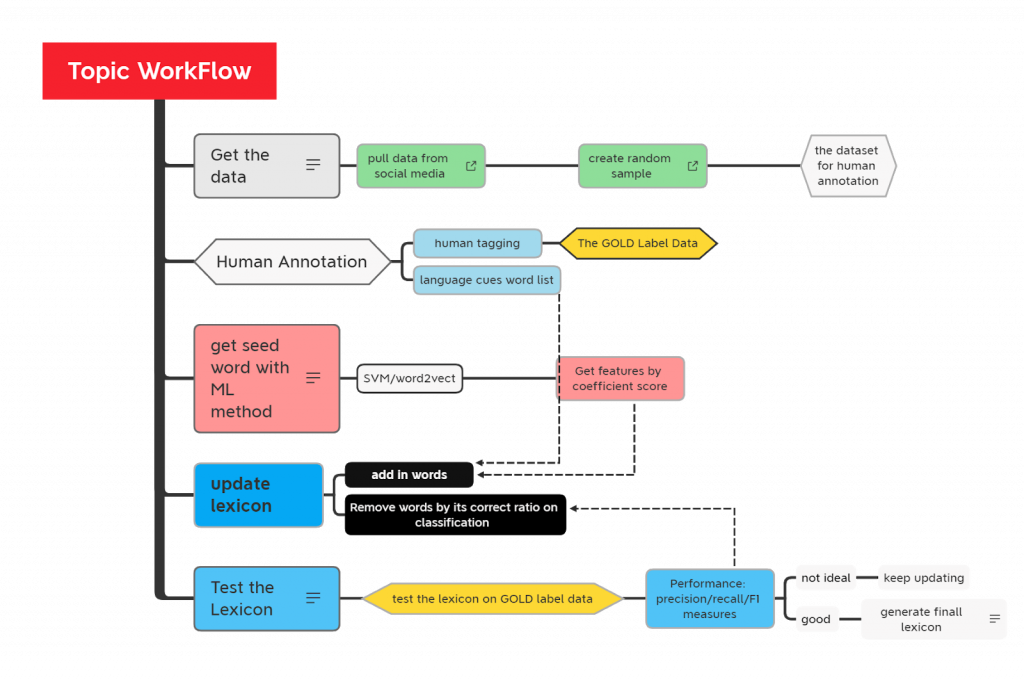
2. Lexicon-based method + Machine Learning Models
Several factors complicate the process of categorizing social media messages into topics. First, the length of typical social media messages is too short for current topic mining approaches, so we are not able to use those kinds of unsupervised learning methods for our task. The second problem is the sparseness of our dataset. Over 45% of the messages in the training and testing sample of 2020’s data have no topic and some categories are too sparse, meaning there are not enough messages in that category to identify lexical patterns associated with the topics. Given the lack of training data, supervised machine learning topic classification is also not appropriate—supervised models cannot learn enough features to resolve problems with sparsity, we therefore devised a lexicon-based approach, which allows us to identify topics in social media messages by searching the messages for the words from our lexicon.
Why can we identify topics just by searching and comparing messages’ textual content with topic lexicons?
Because the topics can be regarded as summaries of each message’s “keywords”. It is like what we do while reading, and this is more obvious when we are reading short messages. Machine and deep learning algorithms find keywords in mathematical ways by calculating the “weight” of the words, referring to their relative importance to the entirety of the message, and determining whether a given word can be used to identify the message’s topic.
For this task, we wanted to be confident that messages tagged with a topic actually discuss that topic. Entries in our lexicon are deterministic rather than probabilistic: we do not assign scores or weights to the language cues (also referred to as feature words). Thus, we used the standard of “sufficiency” to decide which ngrams to include in our lexicon. An n-gram is considered “sufficient” to indicate a topic when we can be confident that it always (or nearly always) refers to a specific topic that we are categorizing. For example, we treat the word “class” as insufficient to indicate any topic on its own. While the term most often occurs in discussions about economic matters (e.g., “middle class”), it can also be used in discussions about other topics such as social programs (e.g. “classroom”). Some n-grams were sufficient for more than one topic. For example, we treat “TPP” (an acronym that references the Trans-Pacific Partnership, a controversial trade treaty in 2016) as sufficient to indicate an economic topic and a foreign policy topic. This means that each time “TPP” appears in a message, we are confident that this message is about economics and foreign policy, and we are confident that no message that mentions “TPP” is not about economics or foreign policy.
We do not include n-grams that have homographs or are polysemous (that is, words that have the same spelling but different meanings) in our lexicon. For example, “arms” as a noun could refer to firearms or to human appendages; given this ambiguity, “arms” is not used as a unigram in our lexicon (though longer unigrams or bigrams containing “arms” are present).
This lexicon method is straightforward, but it performs well because we have put substantial effort in to ensure it works: labeling the datasets, developing topic lexicons, and extending the lexicon by using deep learning and machine learning as an auxiliary method.
2.1. Matching the language cues with Spacy English Language Model
To exactly match the language cues in the messages, we need a powerful tokenizing tool to separate the sentences into proper phrases and do the matching. We applied a pre-trained language model — spaCy2.2 English Language Model — to do this task. This language model is a multi-task convolutional neural network (CNN) model, which is pre-trained on the English language dataset named OntoNotes. The model assigns context-specific vectors and part of speech (POS) tags. It also performs dependency parsing and identifies named entities, such as names of politicians. Thus, this model can efficiently match large terminology lists, making it well suited for our language cue matching goals.
In our experiments to achieve our final lexicons, we input the draft lexicon as a terminology list into the phrase matcher. For example, if we add the word “obamacare” to our lexicon as a match pattern, the model will separate all of the message’s words into n-gram-tokens and then will look for matches between the message and topic lexicon. If the word “obamacare” appears in a message, it will be matched with the topic lexicon before it is passed to the next step of the process, which determines whether the topic-related words that were identified are sufficient to apply the topic corresponding to the topic label.
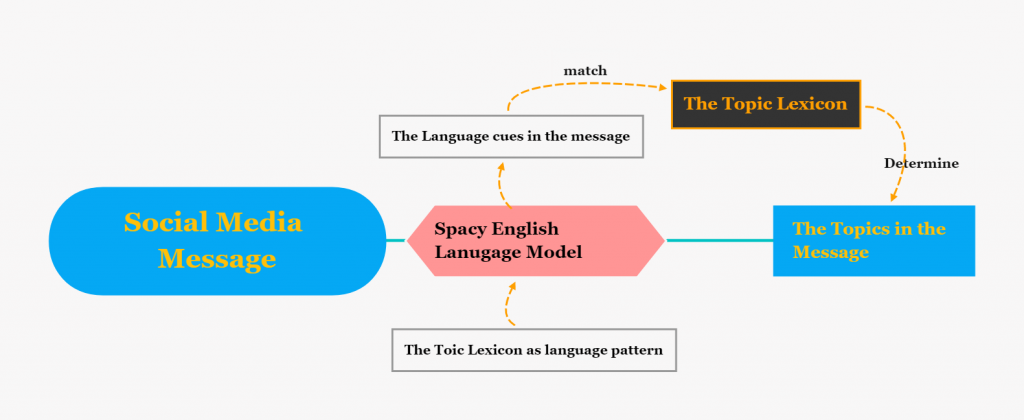
With the help of this English Language Model, we do not have to do the feature engineering. Our tagging process looks for exact matches between n-grams in the lexicon and n-grams in each message. This matching process allows us to be confident that we do not have false positives, which can result, for example, from short words and acronyms in our lexicon that appear within longer words. For example, if “student” appeared in the lexicon but “students” did not, our script would not identify the unigram “students” in a message.
So far we have, in effect, a search engine to identify the topics in the message. The next step is to utilize other Machine Learning algorithms, the Word2vec Embedding and SVM model, to help us devise language cue.
2.2 Finding more language cues with Word2Vec embedding and Support Vector Models (SVM)
We use Word2Vec embedding, which identifies associations between words, to help develop our lexicons. Word2Vec uses a shallow neural network that takes each word’s one-hot encoding as its input. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. We used this algorithm to vectorize the messages’ words and identify clusters of feature words that are associated with one another.
Word2vec helped us identify language cues that humans may not have recognized. For example, if we know that the word “police” is a feature word, with Word2Vec we can identify other words that are closely related to the word “police” in the context of our data. Because these words are shown to be strongly associated with the word “police,” we can consider whether they might also be feature words of the topic that the word “police” belongs to.
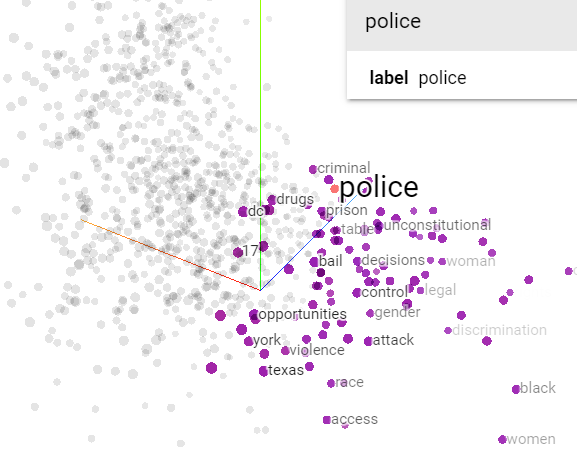
Word2vec only provides unigrams (single words, rather than phrases with multiple words), and we needed more n-gram language cues, so we utilized the Support Vector Machine (SVM) model to perform multi-class classification with bigram and trigram features.
SVM is a supervised machine learning algorithm that has several sub-classes depending on whether the task is linear or nonlinear. The SVM algorithm we applied here is called LinearSVC. SVM is designed for binary classification — that is, forms of classification that only use two categories. Because we have 12 classes of topics, we needed to apply a “one-vs-rest classification” method to adapt the SVM algorithm to our multi-class task. “One-vs-rest” classification involves splitting the multi-class dataset into multiple binary classification problems. A binary classifier is then trained on each binary classification problem and predictions are made using the model that is the most confident.
For each topic class, we sorted the feature words by their importance and selected the top 20. After that, we eliminated any feature words that already exist in our lexicon. The results were reliable—for example, we identified the following feature words of the “economic” category, and the classification precision score (0.82) is confident:
Class: economic
precision = 0.82 Recall = 0.63 F1 = 0.66
Feature words: [‘democrat party’, ‘tax cuts’, ‘help people’, ‘got plan’, ‘stock market’, ‘last year’, ‘teachers value’, ‘transition new’, ‘unemployment rate’, ‘american families’, ‘economy works’, ‘working people’, ‘minimum wage’, ‘working families’, ‘wall street’]
Feature words like “tax cuts”,”stock market” are economic-topic related, while some phrases are not that obvious. Phrases like “american families” and ”teachers value” appeared as important feature words under the economic topic category. This phenomena may be related to the context or due to a limitation of the gold label data. For example, if candidates often mentioned both social programs and economics, the feature words of social programs will also appear in economics. Thus we cooperated with our annotation team and selected the feature words that generated from the ML algorithms.
3. Test and Optimize the Political Topic Lexicon
So far, we have covered the application of a “raw” topic lexicon to the set of 2020 campaign ads. Although its language cues were selected carefully, the performance of the “raw” lexicon did not meet our prediction requirements. We applied the lexicon to the validation dataset and optimized it based on the results. We further tested and evaluated the lexicon by comparing messages’ computationally-assigned topics with our gold-standard human-assigned topics.
Step 1: Find out the miss-classifying seed words
The first step is finding out which seed words that lead to the miss-classification. We designed a script that can tell us the model classifies the text according to which seed words(AKA language cues).
The figure below illustrates the data frame that was produced during the process. The column “words” contains the seed words that were identified in the messages. The column “m_label” ,which means machine labeling, contains the label that the lexicon generated based on the seed words. The Gold Label means the label coded by human annotators.

After running the topic identification model, we compared the gold label which is human-coded, with the label generated by the topic identification model. Then, we verified whether the model classified the message correctly. If the model labels were not correct, then the script will show the seed words under the corresponding categories.

Next, we assembled the mis-classifying seed words for each category into a dictionary. Below are a set of miss-classifying seed words that were incorrectly associated with the ‘social programs’ category.

However, it is possible that those miss-classifying seed words classified other messages correctly. We decided to keep miss-classifying seed words if their ratio of correct to incorrect classifications was relatively high. So, we designed another script to calculate the correct ratio of these miss-classifying seed words. For example, the seed word “affordable health care” labeled 5 messages: 4 labels were correct, while one was incorrect. The correct ratio of seed word “affordable health care” is 4/(4+1) = 0.8. So the phrase “affordable healthcare” has 80% probability to recognize the topic correctly, and we would keep it in the lexicon. We deleted those words whose probabilities are lower than 50%. Below is a sample of the results:

Step 2: Making different sub-version by setting different thresholds
Once we found the miss-classifying seed words and their probabilities of correct classification, we set different thresholds of the probability to decide which words we should keep and which should be removed. We tested thresholds from 50% to 80%, and we made sub-versions of our lexicons with different thresholds within this range. After that, we tested each sub-version on our validation data.
In the tests, we found that different categories require different thresholds to improve their performance. Some categories performed the best when setting the threshold to 80%, while other categories reached the best performance when the threshold was 70% or 60%. Given these differences, instead of using the same threshold for each category, we set different thresholds for different categories. For the categories including education, social programs, safety and governance, we set the threshold as 70%. That meant we kept those words whose probability of identifying the topic correctly was higher than 70%. For the categories including health, immigration, foreign policy and social culture we set the threshold as 60%, and for covid and economic categories the threshold is 80%.
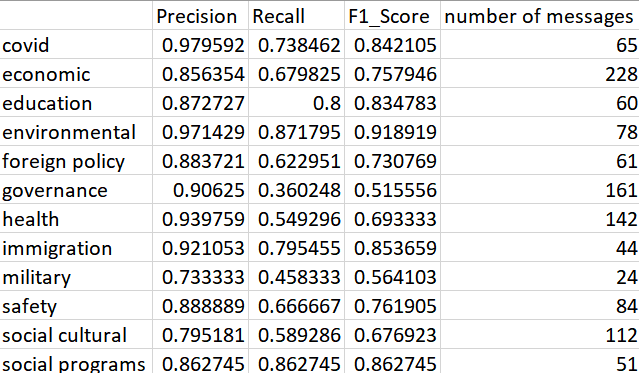
After the iterative process of developing the lexicon, we got the final version of it. We kept the high precision by removing the seed words whose probability of correct identification is lower than the threshold. Although this method hurt the recall of some categories like governance, health, and military, the high precision promised most of the machine labeling are true positives. The following picture shows the results that tested on the 1500 sample data of the 2020 campaign ads from Facebook.
4. Conclusion
We developed a lexicon-based method to identify the topics and optimized this approach with a deep learning model which generated more precise tokenizing. This approach has tremendous potential for helping researchers investigate political topics in social media messages, especially given the shortcomings of unsupervised topic modeling for these texts. We hope that other researchers will find our approach and our lexicon useful in their research. The scripts and the lexicon lists we utilized are available to view on our Github page.